Cosmos Predict2 Video2World ComfyUI Official Example
This guide demonstrates how to complete Cosmos-Predict2 Video2World workflows in ComfyUI
Cosmos-Predict2 is NVIDIA’s next-generation physical world foundation model, specifically designed for high-quality visual generation and prediction tasks in physical AI scenarios.
The model features exceptional physical accuracy, environmental interactivity, and detail reproduction capabilities, enabling realistic simulation of complex physical phenomena and dynamic scenes.Cosmos-Predict2 supports various generation methods including Text-to-Image (Text2Image) and Video-to-World (Video2World),
and is widely used in industrial simulation, autonomous driving, urban planning, scientific research, and other fields.
It serves as a crucial foundational tool for promoting deep integration of intelligent vision and the physical world.GitHub:Cosmos-predict2
huggingface: Cosmos-Predict2This guide will walk you through completing Video2World generation in ComfyUI.For the text-to-image section, please refer to the following part:
Cosmos Predict2 Text to Image
Using Cosmos-Predict2 for text-to-image generation
If you find missing nodes when loading the workflow file below, it may be due to the following situations:
You are not using the latest Development (Nightly) version of ComfyUI.
You are using the Stable (Release) version or Desktop version of ComfyUI (which does not include the latest feature updates).
You are using the latest Commit version of ComfyUI, but some nodes failed to import during startup.
Please make sure you have successfully updated ComfyUI to the latest Development (Nightly) version. See: How to Update ComfyUI section to learn how to update ComfyUI.

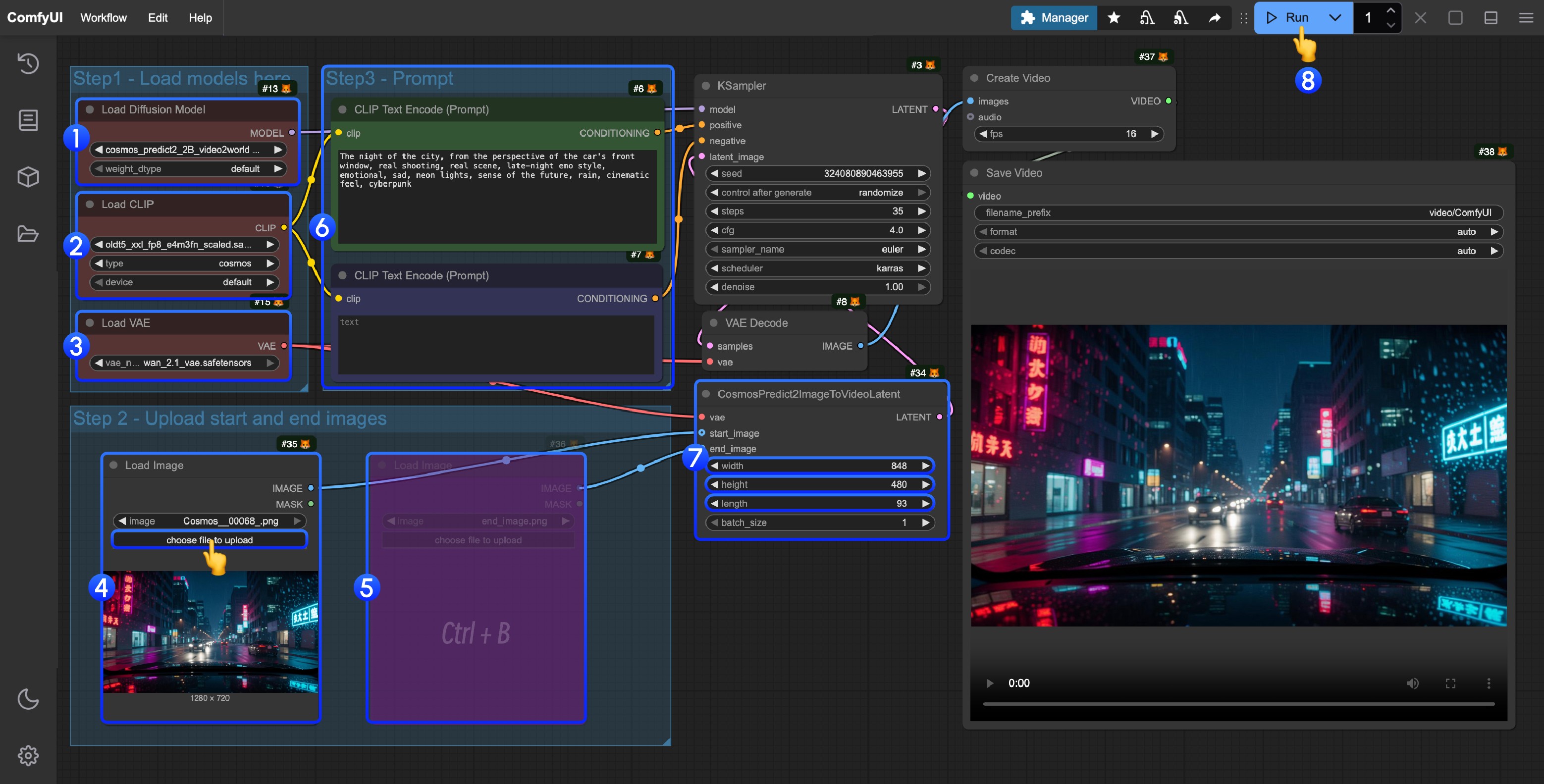 Please follow the steps in the image to run the workflow:
Please follow the steps in the image to run the workflow: